Our technical blog series showcases some of the more compelling problems and deep tech our world class software engineering team wrestles with as they build a fast, powerful and scalable actuarial platform that is used by life insurers globally. In this post, software engineer Jack Robinson explains how our team redesigned our client infrastructure in AWS, to enable faster delivery of new features for our customers.
Here at Montoux, the core of our pricing transformation platform is a monolithic Clojure-based web application that is hosted in AWS. This application contains everything from our front-end Clojurescript client, through to the runtimes for executing actuarial model simulations. Recently, we’ve begun designing “version two” of our platform, which will provide us greater scalability and functionality required by new actuarial applications on the horizon, while also giving us greater flexibility to explore and expand on new fast-growing areas within our company.
One area of work we’d like to improve is the speed in which we deliver features to our customers. Our monolith has suited our small team in the past, but as we continue to grow, shipping a single deployable is becoming more and more untenable. To combat this, we made the decision to begin pulling components out of the application, and treat them as their own standalone service. The first of these components we pulled apart was our Clojurescript-based client.
During our journey in specifying a design in AWS to meet our requirements, we were often met with difficulty in finding examples and information online, often because of the non-trivial nature of this piece of work. In this post, we’d like to show you the infrastructure and architecture we built to support this split client, discussing the goals behind the project, and the advantages, and disadvantages, of the solution we developed.
Separating our frontend client
The code changes required to separate our frontend client from the rest of the application were surprisingly straightforward. When it lived in the monolith, every time a request came to the application, the server would generate (or use) a memoized HTML file, which would set up the basic structure and import the compiled Clojurescript single-page application and CSS. From there, all remaining rendering would be handled by React (via Om) and routing handled by our in-house built browser-side routing. All remaining communication between the client and the backend from that point was via HTTP RPC calls to our server API. What this meant was, the only changes we needed to make to the application was removing the initial load from the server, and modifying our build tools in order to build a separate deployable.
The complexity of this project came from designing the infrastructure. We wanted to be able to deploy a new client or server with little to no impact on the other. This alone would allow us to develop UI features faster, while also cutting down testing effort of the client for server-isolated changes. We also wanted to reduce the complexity in managing our infrastructure as much as possible – the development team we have is still relatively small, so the less time we spend wrangling servers, the better. With these two goals in mind, we settled on an architecture that allows us to meet both.
Our new infrastructure
The architecture we settled on, shown below, makes use of AWS technologies we had at hand; Cloudfront for our CDN, S3 static site hosting to serve up our static assets, and a combination of our existing EC2 instances within Auto Scaling Groups that host our application servers via NGINX.
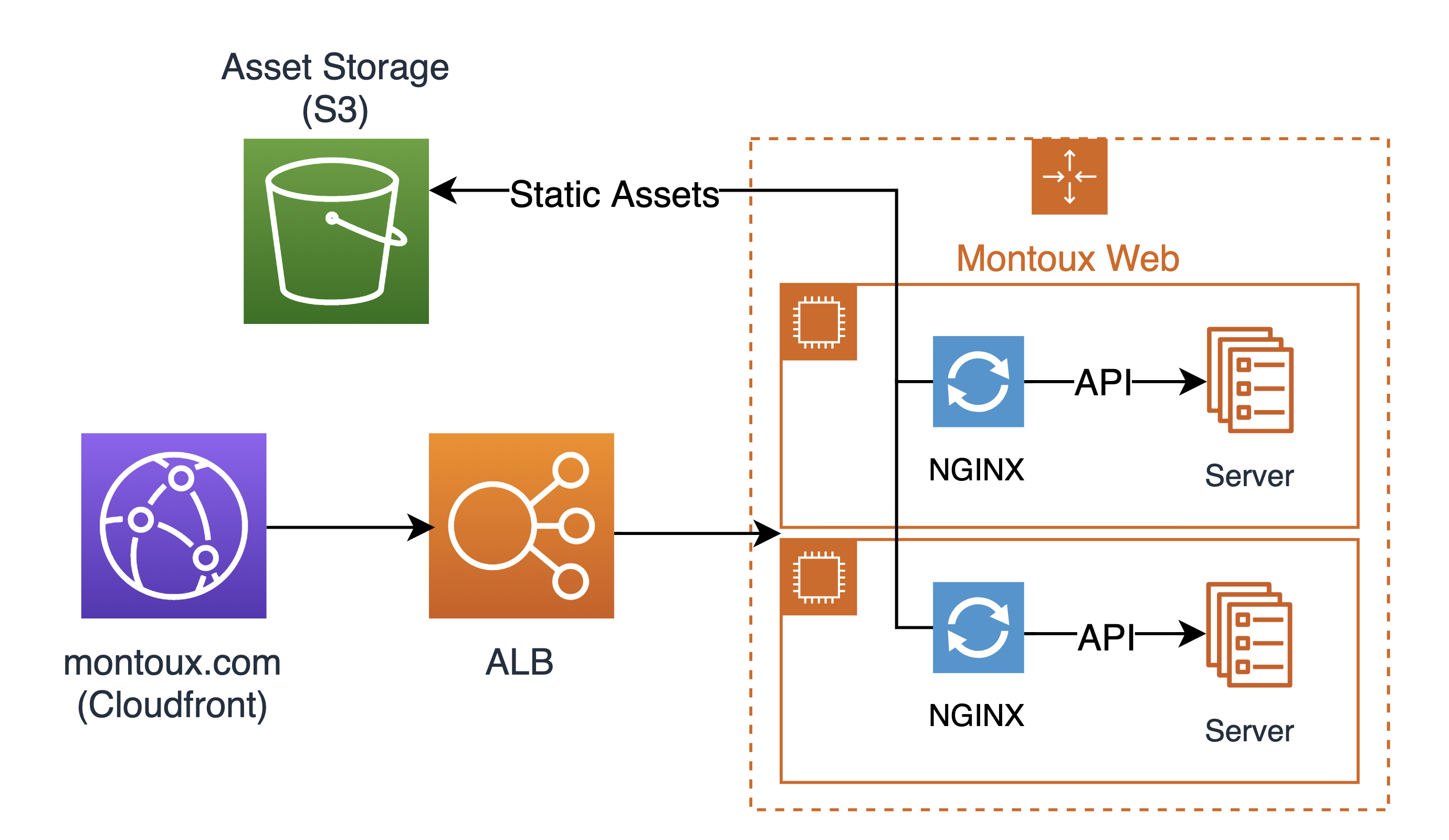
At first, the above infrastructure looks pretty similar to the AWS reference architecture for web applications, but there are subtle differences between them. The general path of a request is:
1. A request comes to “montoux.com”, and is routed to the relevant Cloudfront distribution.
2. Cloudfront handles the request: Cloudfront will either fetch a cached static asset, or attach a custom header describing the client release for the environment, and forward that onto the load balancer.
3. The Load Balancer routes the request to the auto-scaling group (ASG): We place our application servers within an ASG to maximize resiliency – if a server becomes unhealthy, and stops responding to health checks, we can automatically bring up a new one.
4. NGINX handles the request: If the request is for a static asset (that Cloudfront didn’t have cached) or browser-routed path, then we use the custom header attached by Cloudfront, and proxy a request to our S3 bucket. The value in the header lets us ensure that we use the correct client release for the environment. If it’s an API call, then we forward it to the locally running server.
5. We respond to the request: Depending on where the request, ended up, we return the result of the request.
a. For the server, we just return the response from the API.
b. If it was for a static asset, or a browser routed path, we first attempt to retrieve a file from S3. If that returns a 404, then we assume that it’s a browser route, and return the index.html for the client release, and delegate to the client-side routing.
The secret sauce in our implementation is how we route requests via NGINX on our application servers. In the reference architecture, AWS suggests that you make use of the basic routing features of Cloudfront to direct your request to your frontend or your API. As mentioned, our client is a single-page application, meaning we may receive routes that are either bound for our API, or the client-side routing, and the suggestion online was to capture the 404 status code in your Cloudfront distribution, and redirect the requests to your client. Unfortunately, these error handlers are global, meaning that if another origin in our distribution returned 404, then it’d be redirected to our client, which wasn’t always correct — we use 404 status codes for the absence of a requested resource on the API, meaning if a user requested a deleted resource, the server would return an html page. Therefore, we turned to NGINX on our application servers to proxy our requests instead.
Routing requests via NGINX
Online, there are many examples of serving up single-page applications through NGINX, and many suggest the following for your client:
location / {
try_files $uri $uri/ /index.html;
}
try_files will attempt to try each of these paths in order from left to right, and if all else fails, return the index.html, as it’s probably a client-routed request. Unfortunately, this assumes that we host our client alongside our server on the application servers, which means that every release would require an infrastructure update – something we want to avoid. To solve this, we try to mimic similar behavior via proxy_pass:
location @client_index {
proxy_pass http://asset.storage.com/client/index.html;
}
location / {
proxy_pass http://assets.storage.com/client$request_uri;
proxy_intercept_errors on;
error_page 404 = @client_index;
resolver 8.8.8.8;
}
In this snippet, the location for root will attempt to retrieve the asset from the provided URL. Since we’re proxying with a variable in the request, NGINX sometimes requires that you specify a DNS resolver, in this example it is Google’s public DNS server. We also make use of the error_page directive to use the named location @client_index to handle the case where the proxy returns 404. To have error_page work, we need to set proxy_intercept_errors to on. @client_index will just return the index.html file, which will load up the application, and delegate to the client routing.
On top of this, the combination of NGINX with Cloudfront has allowed us to be able to dynamically route the request to the correct version of our static assets in S3. When defining origins in Cloudfront, you are also able to specify headers to append to the request, so in our case, we append the version of the client we’d like to use. When the request reaches NGINX, you can retrieve a header by appending $http_ to the name of the header. Therefore, our proxy pass to our static assets become:
location / {
proxy_pass http://assets.example.com/client/$http_client_version$request_uri;
}
This means that to release the client, all we have to do is deploy new artifacts to our static resources bucket, then update the header within Cloudfront. The server should then route the request to the correct version, all without any server downtime. By partitioning the bucket by client versions, then we can use a single bucket to serve all our different environments, continuing to reduce the scope of infrastructure we have to manage.
The trade-off
A downside to this approach, however, is that Cloudfront is first and foremost a CDN service. While we appreciate the features it gives in terms of caching and geolocated assets, it results in an update to a distribution taking roughly ten or more minutes as it has to deploy changes to all its edge locations. This is rather long, compared to the action of putting some files in an S3 bucket, but for us, every release requires about an hour to take database snapshots, infrastructure tear down and rebuilding — not to mention the time spent waiting for CI pipelines to finish. Ten minutes is already hugely beneficial to our release cycle.
As a whole, the infrastructure we’ve designed accomplishes what it set out to do. We can now deploy our frontend client independently from the remainder of our platform, which will result in quicker and more frequent deployments. Making use of Cloudfront and S3 mean a lot of the heavy lifting is handled by AWS, and making use of NGINX on our existing application servers mean we so much more flexibility in when and how we can release.
About the author
Jack Robinson graduated with a Bachelor of Engineering with Honours from Victoria University in 2017. He began working as an engineer with an internship at Xero, and joined Montoux’s team of software engineers in April 2018. Jack enjoys being part of an insurtech on the verge of scaling rapidly, and tackling the development challenges that come along with that growth.
